Commits on Source (111)
Showing
- README.md 1 addition, 198 deletionsREADME.md
- exercises/exercise-1.md 0 additions, 132 deletionsexercises/exercise-1.md
- exercises/exercise-2.md 0 additions, 121 deletionsexercises/exercise-2.md
- exercises/exercise-3.md 0 additions, 137 deletionsexercises/exercise-3.md
- exercises/exercise-4.md 0 additions, 81 deletionsexercises/exercise-4.md
- exercises/images/2-1.png 0 additions, 0 deletionsexercises/images/2-1.png
- exercises/images/2-2.png 0 additions, 0 deletionsexercises/images/2-2.png
- exercises/images/8-1.png 0 additions, 0 deletionsexercises/images/8-1.png
- exercises/solutions-1.md 0 additions, 98 deletionsexercises/solutions-1.md
- exercises/solutions-2.md 0 additions, 135 deletionsexercises/solutions-2.md
- exercises/solutions-3.md 0 additions, 179 deletionsexercises/solutions-3.md
- grading-gitlab-ci.yml 10 additions, 31 deletionsgrading-gitlab-ci.yml
- labs/example-lab.md 0 additions, 299 deletionslabs/example-lab.md
- labs/grading-and-submission.md 0 additions, 106 deletionslabs/grading-and-submission.md
- labs/images/bloop-update.png 0 additions, 0 deletionslabs/images/bloop-update.png
- labs/images/clone-url.png 0 additions, 0 deletionslabs/images/clone-url.png
- labs/images/gitlab-public-ssh-key.png 0 additions, 0 deletionslabs/images/gitlab-public-ssh-key.png
- labs/images/gitlab-settings.png 0 additions, 0 deletionslabs/images/gitlab-settings.png
- labs/images/hover.png 0 additions, 0 deletionslabs/images/hover.png
- labs/images/import-build.png 0 additions, 0 deletionslabs/images/import-build.png
exercises/exercise-1.md
deleted
100644 → 0
exercises/exercise-2.md
deleted
100644 → 0
exercises/exercise-3.md
deleted
100644 → 0
exercises/exercise-4.md
deleted
100644 → 0
exercises/images/2-1.png
deleted
100644 → 0
{kind=link}
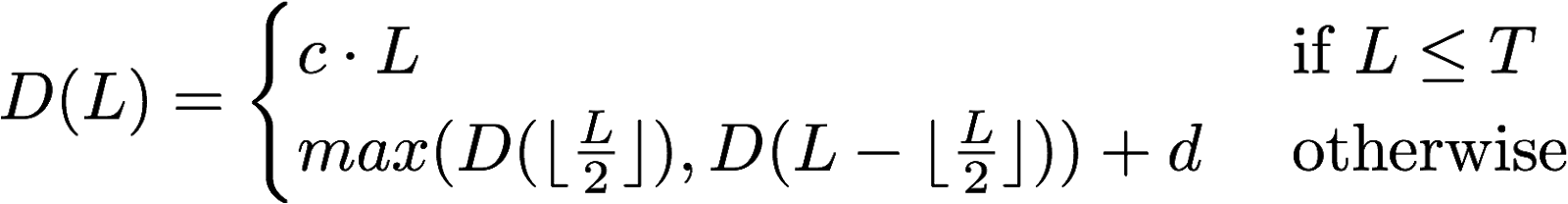
30.4 KiB
exercises/images/2-2.png
deleted
100644 → 0
{kind=link}
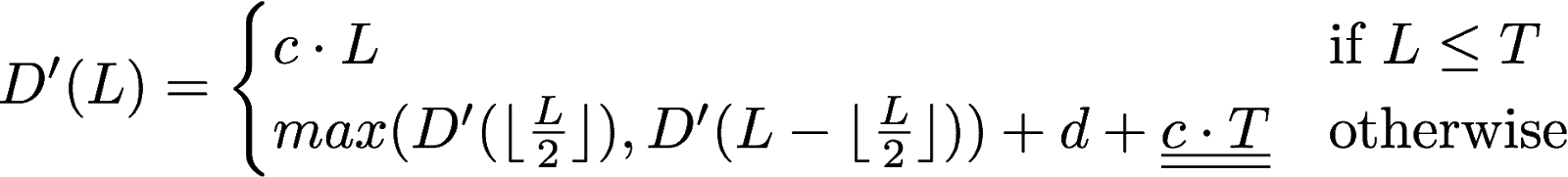
27.5 KiB
exercises/images/8-1.png
deleted
100644 → 0
{kind=link}
8.59 KiB
exercises/solutions-1.md
deleted
100644 → 0
exercises/solutions-2.md
deleted
100644 → 0
exercises/solutions-3.md
deleted
100644 → 0
labs/example-lab.md
deleted
100644 → 0
labs/grading-and-submission.md
deleted
100644 → 0
labs/images/bloop-update.png
deleted
100644 → 0
{kind=link}
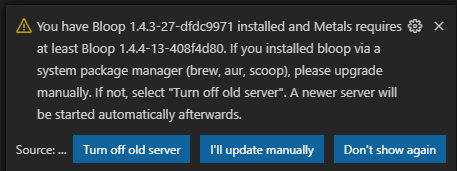
18.1 KiB
labs/images/clone-url.png
deleted
100644 → 0
{kind=link}
41.8 KiB
{kind=link}
111 KiB
labs/images/gitlab-settings.png
deleted
100644 → 0
{kind=link}
24.8 KiB
labs/images/hover.png
deleted
100644 → 0
{kind=link}
163 KiB
labs/images/import-build.png
deleted
100644 → 0
{kind=link}
35.3 KiB